编译和链接是在C/C++软件开发过程中经常发生的两个非常基本的过程,为什么C/C++源代码分割成头文件和源文件? 编译器是如何看到每个部分的? 这如何影响编译和链接? 还有许多类似的问题,无论是在设计C/C++应用程序、为其实现新特性、试图解决bug(尤其是某些奇怪的bug),还是试图让C和C/C++代码协同工作,了解如何编译和链接将节省大量时间。
预处理 编译和链接
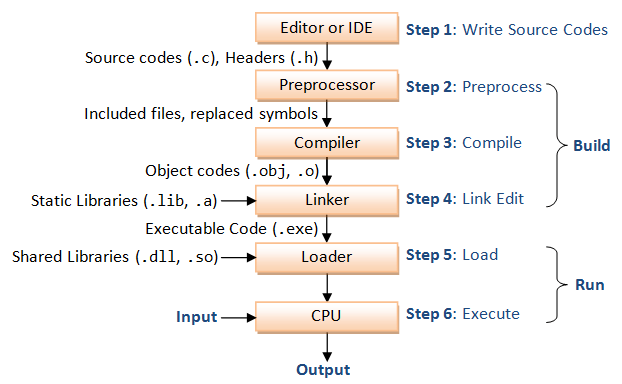
编译器(compiler)是一种计算机程序,它会将某种编程语言写成的源代码(原始语言)转换成另一种编程语言(目标语言)。它主要的目的是将便于人编写、阅读、维护的高级计算机语言所写作的源代码程序,翻译为计算机能解读、运行的低阶机器语言的程序,也就是可执行文件。编译器将原始程序(source program)作为输入,翻译产生使用目标语言(target language)的等价程序。源代码一般为高级语言(High-level language),如Pascal、C、C++、C# 、Java等,而目标语言则是汇编语言或目标机器的目标代码(Object code),有时也称作机器代码(Machine code)。
一个现代编译器的主要工作流程如下:
源代码(source code)→ 预处理器(preprocessor)→ 编译器(compiler)→ 汇编程序(assembler)→ 目标代码(object code)→ 链接器(linker)→ 可执行文件(executables),最后打包好的文件就可以给电脑去判读运行了。
每个c++源文件都需要编译成目标文件。编译多个源文件产生的目标文件然后链接到可执行文件、共享库或静态库。c++源文件通常具有.cpp、.cxx或.cc扩展名后缀。c++源文件可以包含其他文件,称为头文件,使用#include指令。头文件具有.h、.hpp或.hxx这样的扩展名,或者完全没有扩展名,就像c++标准库和其他库的头文件(如Qt)中那样。扩展对于c++预处理器来说并不重要,它会将包含#include指令的行替换为所包含文件的全部内容。
编译器对源文件执行的第一步是在其上运行预处理器。只有源文件被传递给编译器(进行预处理和编译)。头文件不传递给编译器。相反,它们是从源文件中包含的。在所有源文件的预处理阶段,每个头文件都可以被打开多次,具体取决于有多少源文件包含了它们,或者有多少源文件中包含的其他头文件也包含了它们(可能有许多间接级别)。另一方面,编译器(和预处理器)只会在源文件被传递给编译器时打开一次。
对于每一个C/C++源文件, 当它发现一个#include指令时,预处理器通过插入内容将构建一个翻译单元;与此同时,若找到条件编译模块的求值结果为false时,它会剥离代码源文件和指令的头。它还将完成一些其他任务,比如宏替换。一旦预处理器完成创建(有时是巨大的)转换单元,编译器就开始编译阶段并生成目标文件。
GNU C和C++编译器分别称为gcc和g++。
| 选项 | 解释 |
|---|---|
| -c | 只编译并生成目标文件。 |
| -E | 只运行 C 预编译器。 |
| -g | 生成调试信息。GNU 调试器可利用该信息。 |
| -o FILE | 生成指定的输出文件。用在生成可执行文件时。 |
| -O0 | 不进行优化处理。 |
| -O 或 -O1 | 优化生成代码。 |
| -O2 | 进一步优化。 |
| -O3 | 比 -O2 更进一步优化,包括 inline 函数。 |
| -w | 不生成任何警告信息。 |
| -Wall | 生成所有警告信息。 |
下面是一个示例:
1 | // hello_c.c |
1 | // hello_cpp.cpp |
通过以下方法创建预处理文件:
1 | $ gcc -E hello_c.c -o hello_c.ii |
看行数:
1 | $ wc -l hello.ii |
在我的机器中hello.ii有544行代码, hello_cpp.ii有41840行代码。我们可以看到,编译器必须编译一个比我们看到的简单源文件大得多的文件。这是因为包含了头文件。在我们的示例中,我们只包含了一个header。随着我们不断包含头文件,翻译单元变得越来越大。
1 | $ gcc -c hello_c.c |
1 | $ g++ -c hello_cpp.cpp |
源文件如何导入和导出符号
有一个简单的C(不是C++)源文件名为 print_num.c,它导出了两个函数,一个用于打印整数,另一个用于打印浮点数:
1 | int printI(int v) { |
编译它以创建 print_num.o 目标文件:
1 | gcc -c print_num.c |
现在看看这个目标文件导出和导入的符号:
1 | nm print_num.o |
没有符号被导入,导出两个符号 printF和printI。这些符号被导出为.text段(T)的一部分,因此它们是函数名、可执行代码。
标准的方法是创建一个头文件来声明它们,并将它们包含在我们想要调用的任何源文件中。头文件可以有任何名称和扩展名。下面的例子print_num.h:
1 |
|
那些ifdef/endif条件编译块是什么?如果我从C源文件中引用这个头文件,我希望它成为:
1 | int printI(int v); |
但如果如果我从C++源文件中引用这个头文件,我希望它成为:
1 | extern "C" { |
C语言不知道关于extern “C”指令的任何事情,但是c++知道,它需要将这个指令应用到C函数声明中。这是因为c++重整了函数(和方法)的名称,因为它支持函数/方法重载,而C不支持。
这可以在名为print.cpp的c++源文件中看到:
1 |
|
有两个名称相同的函数(printNum),只是它们的参数类型不同:int或float。函数重载是C++的一个特性,在C中没有。为了实现这个特性并区分这些函数,C++修改了函数名,我们可以在导出的符号名中看到(我只从nm的输出中选择相关的):
1 | g++ -c print.cpp |
在我的系统中,这些函数被导出为float版本的__Z8printNumf和int版本的__Z8printNumi。C++中的每个函数名都是混乱的,除非声明为extern “C”。在print中有两个函数是用C链接声明的。printSumInt和printSumFloat。
因此,它们不能被重载,或者它们的导出名称将是相同的,因为它们没有被破坏。我必须通过在它们的名字后面加上整型或浮点数来区分它们。因为它们没有被破坏,所以可以从C代码中调用它们,我们很快就会看到。
要像在C++源代码中那样查看被破坏的名称,我们可以在nm命令中使用-C (demangle)选项。同样,我将只复制输出相同的相关部分:
1 | nm -C print.o |
使用这个选项,我们看到的不是__Z8printNumf,而是printNum(float),不是__ZNSt3__14coutE,而是std::__1::cout,这是更人性化的名称。
我们还看到C++代码调用了C代码:print.cpp调用了printI和pringF,它们是在print_num.h中声明为具有C链接的C函数。这可以从print.o的nm输出中看出。上面一些未定义的(U)符号:printF, printI和std::cout。那些未定义的符号应该在一个对象文件(或库)中提供,该对象文件将在链接阶段与这个对象文件输出链接在一起。
到目前为止,我们只是将源代码编译成目标代码,还没有链接。如果我们没有将包含这些导入符号定义的对象文件与此对象文件链接在一起,那么链接器将停止,并出现“丢失符号”错误。
还要注意,由于print.cpp是一个C++源文件,是用C++编译器(g++)编译的,因此其中的所有代码都被编译为C++代码。带有C链接的函数,如printNumInt和printNumFloat,也是可以使用C++特性的C++函数。只是符号的名称与C兼容,但代码是C++,这一点可以从两个函数都在调用重载函数(printNum)这一事实看出,如果在C中编译printNumInt或printNumFloat,就不会发生这种情况。
现在让我们看看 print.hpp,一个头文件,可以包含从C或C++源文件,它将允许从C和C++调用printNumInt和printNumFloat,以及从C++调用printNum:
1 |
|
如果我们从C源文件包括它,我们只想看到:
1 | void printNumInt(int v); |
不能从C代码中看到printNum,因为它的名字被破坏了,所以我们没有(标准的和可移植的)方法来为C代码声明它。是的,我可以声明为:
1 | void __Z8printNumi(int v); |
链接器不会抱怨,因为这正是我当前安装的编译器为它发明的名称,但我不知道它是否适用于您的链接器(如果您的编译器生成了一个不同的错误名称),甚至适用于我的链接器的下一个版本。我甚至不知道如果调用将按预期工作,因为不同的调用约定的存在(如何传递参数和返回值返回)。 它是与具体编译器相关的,可能是不同的C和C++调用(特别是对于C++函数成员函数和接收这个指针作为参数)。
编译器可能会对普通C++函数使用一种调用约定,如果它们被声明为具有extern “ C “链接,则使用另一种调用约定。因此,欺骗编译器说一个函数使用C调用约定,而实际上它使用C++,同时,如果每个函数使用的约定在编译工具链中碰巧不同,可能会产生意想不到的结果。
混合C和C++代码有标准的方法,从C中调用C++重载函数的标准方法是将它们封装在带有C链接的函数中,就像我们用printNumInt和printNumFloat封装printNum一样。
如果我们在一个C++源文件中引用print.hpp,__cplusplus预处理器宏将被定义,该文件将被视为:
1 | void printNum(int v); |
这将允许C++代码调用重载函数printNum或其封装层printNumInt和printNumFloat。
现在让我们创建一个包含main函数的C源文件,它是程序的入口点。这个C主函数将调用printNumInt和printNumFloat,也就是说,将使用C链接调用这两个C++函数。记住,这些是C++函数(它们的函数体执行C++代码),只是它们的名称没有被打乱。文件命名为c-main.c:
1 |
|
编译生成目标文件:
1 | gcc -c c-main.c |
并查看导入/导出符号:
1 | nm c-main.o |
如预期的那样,它导出main并导入printNumFloat和printNumInt。
要将它们链接到一个可执行文件中,我们需要使用C++链接器(g++),因为至少要链接的一个文件print.o是用c++编译的:
1 | $ g++ -o c-app print_num.o print.o c-main.o |
执行产生预期的结果:
1 | $ ./c-app |
现在让我们尝试使用一个c++主文件,名为cpp-main.cpp:
1 |
|
编译并查看cpp-main的导入/导出符号 cpp-main.o对象文件:
1 | $ g++ -c cpp-main.cpp |
它导出main,并导入C链接printNumFloat和printNumInt,以及两个被修改的printNum版本。
你可能想知道为什么主符号没有导出为一个像main(int, char**)这样的混乱符号从这个C++源文件,因为它是一个C++源文件,它没有定义为extern “C”。main是一个特殊的实现定义函数,无论它是在C或C++源文件中定义,我的实现似乎都选择使用C链接。
链接和运行程序会得到预期的结果:
1 | $ g++ -o cpp-app print_num.o print.o cpp-main.o |
参考文献:
[1] https://en.wikipedia.org/wiki/Compiler
[2] https://www3.ntu.edu.sg/home/ehchua/programming/cpp/gcc_make.html
[3] http://www.cplusplus.com/doc/tutorial/introduction/
[4] https://en.cppreference.com/w/cpp/compiler_support
[5] https://docs.oracle.com/cd/E19957-01/806-3572/Using.html